
深度學(xué)習(xí)技術(shù),特別是神經(jīng)網(wǎng)絡(luò),已經(jīng)在圖像和語音跟蹤領(lǐng)域取得了不小的進展。這些技術(shù)可以應(yīng)用于物聯(lián)網(wǎng)設(shè)備,實現(xiàn)更加智能化的交互和控制。物聯(lián)網(wǎng)、人工智能和大數(shù)據(jù)的融合正在開啟一個智能化的新紀(jì)元。這種融合不僅推動了技術(shù)革新,還為各行各業(yè)帶來了深刻的變革。隨著技術(shù)的不斷發(fā)展,這一融合將推動智能家居、智能城市、...
AI智能基本參數(shù)
- 品牌
- 慧視科技
- 型號
- 可定制
- 輸出信號
- 可定制
- 制作工藝
- 可定制
- 材質(zhì)
- 可定制
- 材料物理性質(zhì)
- 可定制
AI智能企業(yè)商機
我們教一個小孩識物的時候,比如“蘋果”,首先要讓他反復(fù)的看到“蘋果”,他便能認(rèn)識“蘋果”;他可能會認(rèn)錯,把“梨”認(rèn)成“蘋果”,這個時候應(yīng)該幫他指出來。小孩看到的“蘋果”越多,辨識的能力就越強。基于深度神經(jīng)網(wǎng)絡(luò)的人工智能,讓機器具備理解的能力,基本過程就像教一個小孩認(rèn)蘋果一樣。首先要有大量的數(shù)據(jù),比如“蘋果”的圖片;同時,要增加大量機器會認(rèn)錯的“負樣本”,比如“梨”的圖片;然后經(jīng)過一個深度神經(jīng)網(wǎng)絡(luò),反復(fù)學(xué)習(xí),然后獲得一個有效的識別模型。對于快消商品的識別,我們不僅要認(rèn)出一個瓶子包裝,還要認(rèn)出是一瓶酸奶還是啤酒;不僅要認(rèn)出酸奶,還要認(rèn)出是哪個品牌的酸奶,甚至是哪個口味和規(guī)格。要讓機器能夠準(zhǔn)確識別成千上萬的快消商品SKU,是一項極其龐大而復(fù)雜的AI工程。人工智能和機器學(xué)習(xí)可以幫助施工團隊更有效地管理資源,從而節(jié)省成本。陜西智慧園區(qū)AI智能
AI智能
目標(biāo)檢測(Object Detection)的任務(wù)是找出圖像中所有感興趣的目標(biāo)(物體),確定它們的類別和位置,是計算機視覺領(lǐng)域的主要問題之一。由于各類物體有不同的外觀、形狀和姿態(tài),加上成像時光照、遮擋等因素的干擾,目標(biāo)檢測一直是計算機視覺領(lǐng)域相當(dāng)有有挑戰(zhàn)性的問題。隨著深度學(xué)習(xí)的不斷發(fā)展,目標(biāo)檢測的應(yīng)用愈加廣,現(xiàn)已被應(yīng)用于農(nóng)業(yè)、交通和醫(yī)學(xué)等眾多領(lǐng)域。與基于特征的傳統(tǒng)手工方法相比,基于深度學(xué)習(xí)的目標(biāo)檢測方法可以學(xué)習(xí)低級和高級圖像特征,有更好的檢測精度和泛化能力湖北行業(yè)用AI智能慧視光電開發(fā)的慧視AI圖像處理板,采用了國產(chǎn)高性能CPU。

我國作為世界上鄰國**多、邊境線長的國家之一,擁有長達2.2萬公里的邊境線。很多不法分子常常利用邊境復(fù)雜環(huán)境的特點進行非法偷渡,復(fù)雜的邊境環(huán)境給我們的邊防安防造成了極大的阻礙,但是即使面對這樣的環(huán)境,邊境安防也不可松懈。隨著技術(shù)的發(fā)展,邊境安防的模式也在不斷進步,以往,我們都是依靠邊境安防警察夜以繼日的巡邏,漫長的邊境線讓我們的邊境警察難以實現(xiàn)全覆蓋。如今,隨著邊境安防系統(tǒng)的逐步建立,更加高效,更加省力的特點,讓邊境安防事半功倍。
對進銷存、訂貨、選品、商業(yè)選址都很有幫助。大數(shù)據(jù)預(yù)測的算法會根據(jù)近幾年的數(shù)據(jù),加上天氣、節(jié)日、時間段的影響,機器就可以處理進銷存的訂貨、研究用戶的消費行為,對未來的選品和定價都非常有幫助。圖像識別、聲音識別、數(shù)字化人工智能算法三大技術(shù)只能搭起機器識別的骨架,但如何讓零售變的更加智能,還需要更深層次的技術(shù)做支持,如何在表層技術(shù)的基礎(chǔ)上進行更深層次的剖析,是現(xiàn)在智能零售業(yè)急需解決的問題,下面我們就智能零售中運用比較多的技術(shù)——圖像識別技術(shù)進行簡要的解析。AI自動圖像標(biāo)注平臺SpeedDP。

隨著智能跟蹤設(shè)備的需求量越來越大,對技術(shù)的要求越來越高,市場上出現(xiàn)了專業(yè)的圖像跟蹤板研發(fā)生產(chǎn)廠家,例如成都慧視光電技術(shù)有限公司和一些高校研究所團隊,而且為了快速提升跟蹤的識別率、快速升級迭代,也出現(xiàn)了專業(yè)的工具,例如百度的AI訓(xùn)練工具,除此之外,類似的還有成都慧視光電技術(shù)有限公司的SpeedDP深度學(xué)習(xí)算法開發(fā)平臺。該平臺提供豐富的算法參數(shù)設(shè)置接口,滿足不同用戶業(yè)務(wù)場景的定制化需求。這是成都慧視光電技術(shù)有限公司針對于零基礎(chǔ)的AI訓(xùn)練使用者開發(fā)的平臺。工程師以RK3588核心板為基礎(chǔ)進行定制開發(fā),讓攝像頭更加智能高效,能夠輸出高清流的圖像視頻。四川慧視光電AI智能目標(biāo)跟蹤
慧視RK3588圖像跟蹤板支持AI智能識別目標(biāo)(人、車)。陜西智慧園區(qū)AI智能
圖像識別技術(shù)的高價值應(yīng)用就發(fā)生在你我身邊,例如視頻監(jiān)控、自動駕駛和智能醫(yī)療等,而這些圖像識別進展的背后推動力是深度學(xué)習(xí)。深度學(xué)習(xí)的成功主要得益于三個方面:大規(guī)模數(shù)據(jù)集的產(chǎn)生、強有力的模型的發(fā)展以及可用的大量計算資源。對于各種各樣的圖像識別任務(wù),精心設(shè)計的深度神經(jīng)網(wǎng)絡(luò)已經(jīng)遠遠超越了以前那些基于人工設(shè)計的圖像特征的方法。盡管到目前為止深度學(xué)習(xí)在圖像識別方面已經(jīng)取得了巨大成功,但在它進一步廣泛應(yīng)用之前,仍然有很多挑戰(zhàn)需要我們?nèi)ッ鎸Αj兾髦腔蹐@區(qū)AI智能
與AI智能相關(guān)的文章
甘肅視頻識別AI智能服務(wù)平臺
- 重慶電力運維AI智能提供商 2025-07-13
- 河南行業(yè)用AI智能算法 2025-07-13
- 湖南邊海防AI智能視覺 2025-07-12
- 云南開發(fā)AI智能目標(biāo)跟蹤 2025-07-12
- 吉林應(yīng)急救援AI智能解決方案 2025-07-12
- 四川智慧交通AI智能明火識別 2025-07-12
- 云南智慧工地AI智能煙霧識別 2025-07-12
- 貴州AI智能高效處理 2025-07-12
- 湖北智慧園區(qū)AI智能服務(wù)平臺 2025-07-12
- 深度學(xué)習(xí)AI智能應(yīng)用 2025-07-12
- 吉林應(yīng)急救援AI智能人臉識別 2025-07-12
- 貴州專業(yè)AI智能處理板 2025-07-11
與AI智能相關(guān)的產(chǎn)品



與AI智能相關(guān)的新聞
-
貴州周界入侵AI智能監(jiān)控 2025-07-11 12:02:46利用圖像處理技術(shù)實現(xiàn)導(dǎo)彈的遠程打擊是一項運用了比較長時間的技術(shù),相比于現(xiàn)代化的電子控制,它具備低受干擾的特點,特別是無人機在軍備領(lǐng)域的廣泛應(yīng)用,圖像處理的作用重新受到重視。遠程打擊時,需要對整個彈的識別能力進行深度學(xué)習(xí)訓(xùn)練,不斷的訓(xùn)練能夠讓AI更加聰明,讓AI知道該打擊什么,從而提升打擊精度。在前期...
-
遼寧智慧養(yǎng)老AI智能高效處理 2025-07-11 15:03:12在許多領(lǐng)域,無人機的作業(yè)環(huán)境相對復(fù)雜,需要識別處理圖像背景目標(biāo)眾多,這種環(huán)境下,要想實現(xiàn)更高精度的檢測識別效果,圖像處理板的性能至關(guān)重要。在慧視光電開發(fā)的多款圖像處理板中,Viztra-HE030圖像處理板以6.0TOPS得以勝任。這款板卡采用了瑞芯微旗艦級芯片RK3588,8nmLP制程,搭載八核...
-
湖南深度學(xué)習(xí)AI智能 2025-07-11 15:03:11低空經(jīng)濟成為當(dāng)下火熱的行業(yè)之一,各行各業(yè)都想利用無人機為自己服務(wù),但是卻面臨一個問題,專業(yè)人才嚴(yán)重不足。有關(guān)數(shù)據(jù)顯示,我國無人機經(jīng)營性企業(yè)已超過1.7萬家,全國實名登記的無人機已超過200萬架。而無人機人才的缺口卻多達100萬,這就給低空經(jīng)濟的快速發(fā)展按下了慢速鍵。各大高校陸續(xù)建設(shè)無人機專業(yè),但是四...
-
重慶算法定制AI智能明火識別 2025-07-11 19:02:39長時間一直進行這樣的圖像標(biāo)注工作,那無疑是枯燥而乏味的,手酸不說,更多的是精神上的折磨,進而效率大打折扣。但這又是算法提升的必要途徑,無法跳過,當(dāng)項目緊急時,甚至需要多人加班加點趕進度。這樣的痛苦現(xiàn)狀急需改變!慧視光電的算法工程師為了提高這一的效率,開發(fā)了一個深度學(xué)習(xí)算法開發(fā)平臺SpeedDP。它的...
與AI智能相關(guān)的問題
新聞資訊
產(chǎn)品推薦
-

湖南穩(wěn)定目標(biāo)識別辦公軟件
2025-07-14 -

江西國產(chǎn)目標(biāo)識別
2025-07-14 -

安徽省時省力目標(biāo)識別遠程控制
2025-07-14 -

流暢圖像處理板什么價格
2025-07-13 -

浙江圖像處理板技術(shù)含量
2025-07-13 -

吉林移動目標(biāo)識別解決方案
2025-07-13 -

江蘇目標(biāo)識別鄭重承諾
2025-07-13 -

重慶電力運維AI智能提供商
2025-07-13 -
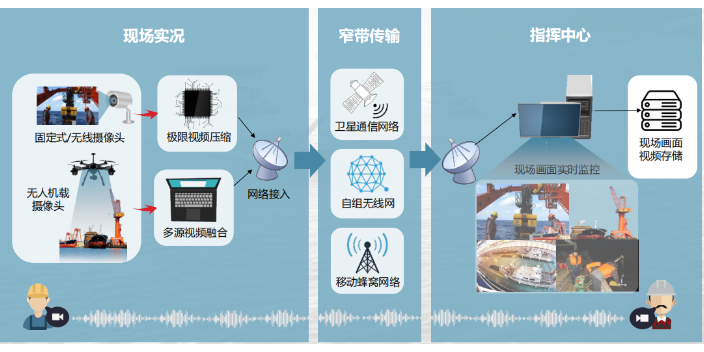
重慶安保視頻壓縮與傳輸不降低畫質(zhì)
2025-07-13